| BibTeX | @inproceedings{Rola2026specpool,
title = {{SpecPool}: {Storage}-Layer Speculation for Parallel Smart Contract Execution},
author = {Francisco Rola and Miguel Matos and Michał Nazarewicz and Paolo Romano},
booktitle = {46th IEEE International Conference on Distributed Computing Systems (ICDCS)},
year = 2026,
month = jun,
day = {22--25},
location = {Seoul, South Korea},
publisher = {IEEE},
address = {Piscataway, USA}}
} |
|---|
| IEEE | F. Rola, M. Matos, M. Nazarewicz, and P. Romano, “SpecPool: Storage-Layer Speculation for Parallel Smart Contract Execution,” 2026 46th IEEE International Conference on Distributed Computing Systems (ICDCS), Seoul, South Korea, June 2026 I’m pleased to share the ‘SpecPool: Storage-Layer Speculation for Parallel Smart Contract Execution’ paper which I’ve co-written. It introduces a mechanism for parallel speculative smart contract execution at the mempool stage. With improvements of consensus protocols and increased computation demands on blockchains, the transaction execution time becomes blockchain’s bottleneck. SpecPool predicts a likely transaction block order and executes smart contracts available in mempool while they await consensus. Once the final block order is established, SpecPool validates each execution maximising concurrency while preserving consensus-consistent ordering. Operating at the storage layer, SpecPool requires no modifications to virtual machine semantics or consensus protocols, simplifying adoption in existing blockchain systems. Experiments on the Injective blockchain demonstrate up to a 60× reduction in block validation latency and 20% throughput improvement over prior parallel execution approaches The author copy of the ‘SpecPool’ paper is now available for download (PDF, 422 kB).This article continues the series about approximating circles using Bézier curves. Preceding parts analysed linear and quadratic curves. This entry examines cubic Bézier curves. It presents a construction of a spline which approximates a circle and derives practical formulæ based on different optimisation criteria. Table of Contents
 Fig. 1 Inkscape highlighting a joint (a blue diamond) and adjacent control points (blue circles). Fig. 1 Inkscape highlighting a joint (a blue diamond) and adjacent control points (blue circles). Cubic Bézier curves are available in many popular tools. They are widely used in vector graphics editing and animation software, and provide flexibility while remaining intuitive to edit. For example, Fig. 1 presents Inkscape’s Node Tool highlighting a joint and two control points adjacent to it. Dragging the points offers a user-friendly way to modify the shape. A cubic Bézier curve uses four control points: \(\def\P{\mathbf P}\P_0\) through \(\P_3\) and is defined by the following parametric function: $$\def\tau2k{\frac τ{2k}} \def\D{Δ\mathbf P} \def\O{\mathbf O} \def\R2{\mathtt{R2}} \def\V{\mathbf V} \def\VR{\mathbf V^⟂} \def\argmin{\operatorname*{arg\,min}} \def\lerp{\operatorname{lerp}} B(t)=(1-t)^3\P_0 + 3(1-t)^2t\P_1 + 3(1-t)t^2\P_2 + t^3\P_3$$ 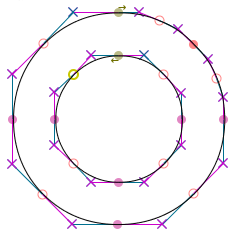 Fig. 1 An outline of a degree symbol from DejaVu Sans font. Fig. 1 An outline of a degree symbol from DejaVu Sans font.The previous article in the series explored drawing circles with linear Bézier curves. This article continues by showing how to use quadratic curves. Table of Contents
A quadratic Bézier curve uses three control points. The first and last points are the endpoints, while the middle one provides control over the curve’s shape. This additional control lets quadratic curves approximate curved shapes more accurately. Although they’re less expressive than higher-order curves, quadratic curves are widely used thanks to their balance of computational complexity and shape control — most notably in computer fonts (see Fig. 1) where the relative simplicity enables efficient rendering algorithms.1  Fig. 1 Star Castle video game draws circles as regular polygons. (Click to open the image). Fig. 1 Star Castle video game draws circles as regular polygons. (Click to open the image).Some systems do not provide a circle primitive; in those cases, circles need to be approximated using different shapes. For example, many fonts are limited to quadratic Bézier curves,1 and even though Adobe Animate includes a circle tool, it represents circles using cubic Bézier curves instead.2 Such approximations are common in video games as well (see Fig. 1), where round objects still present rendering challenges. This post is first in a series of articles about approximating circles. It introduces linear Bézier curves, and how to approximate a circle using linear Bézier curves. The next two articles cover quadratic and cubic curves, which produce progressively smoother results. Table of Contents
Recent carykh’s Adobe Animate’s circles aren’t real circles video demonstrates how Adobe Animate approximates circles with Bézier curves. At the end of the video Cary demonstrated what happens to the shape if control points are pushed to extreme, but using imprecise mouse manipulation, the effect wasn’t quite precise. The effect can be achieved with SVG1 quite easily and so I present it below:Demonstration of a circle approximated via eight cubic Bézier curves as the handles are pushed to extreme way past when the shape resembles a circle. The graphic includes a purple circle; a red octagon inscribed in the circle; and a green spline which consists of eight cubic Bézier curves with anchor points in vertices of the octagon. As I looked more into the subject I’ve decided to write a full series about approximating circles with Bézier curves with different degrees. The subject is more complex than one might imagine and it wouldn’t quite fit as a single post. That’s why I’ve decided to split it into multiple articles with this post acting as a table of contents: - ‘Drawing circles with polygons’ which turns out to be more involved with more than one way of doing it. I will also present mathematically ‘best’ way to draw a polygon so that it resembles circle the most.
- ‘Drawing circles with quadratic Bézier curves’ with discussion of smoothness and mathematical derivation of the best parameters to use depending on number of segments in the curve.
- ‘Drawing circles with cubic Bézier curves’ which allow for more degrees of freedom and thus looking at more constraints and trade-offs in drawing a circle approximation.
Introduced last century, favicons help users identify tabs in a crowded browser. Originally limited to the ICO format, they can now leverage Scalable Vector Graphics (SVG). This vector format not only scales perfectly to different sizes but also unlocks dynamic features which this article explores, namely: When Linux desktop adoption is discussed, some point out the lack of graphical user interfaces (GUI) and the necessity of using command-line interface (CLI) tools or editing text files as a reason more people don’t use Linux-based systems. Such characterisation misses how much Linux has changed. The notion that the terminal is a major barrier is outdated and ignores the fact that most users never need to touch it. An assertion that users should not need the terminal for common tasks is different from a claim Linux distributions lack GUIs. The GoodFirst, let’s recognise how Linux has improved. In the ’90s and ’00s one had to manually edit cryptic modelines to get their display working. A mistake could lead to a damaged monitor. Nowadays, the main complication is picking a distribution which includes Nvidia drivers. And that’s not the only thing that has changed. Installing software often required interacting with the CLI; now graphical software managers — which work not unlike app stores many users are familiar with — are common. Handling WiFi used to require messing with wpa_supplicant; now it’s done through an icon in the system tray. Bambu Lab, a company once celebrated for its high-quality and user-friendly 3D printers, has recently hit a trifecta of questionable behaviour: enshittification of their products, threatening legal action to silence critics and violation of free software licences. Fortunately, several organisations have stepped in to fight for customer rights and free software. Among those, Software Freedom Conservancy (SFC) is asking for volunteers and donations to help fight Bambu’s corporate overreach. It is unclear why Americans write dates in month-day-year format. What is clear is that it makes little sense and differs from the way most of the world writes dates resulting in confusion. While human puzzlement is well-documented (something I’ve written about as well), equally critical is how screen readers and machine translation behave. When handling dates in a free-form text, software relies on fragile heuristics. For example, DeepL and Google Translate decide seemingly randomly whether to treat dates the British or American way as demonstrated on figure below. The behaviour can change depending on the use of padding zero, existence of other dates in the translated fragment or surrounding text.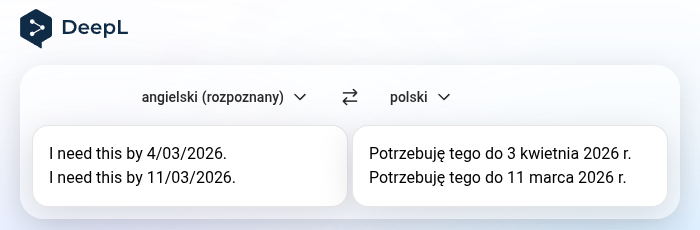 | BibTeX | @article{Nazarewicz2026ntp,
title = {{NTP}-over-{HTTP}},
author = {Michał Nazarewicz},
journal = {{Paged Out!}},
year = 2026,
month = feb,
number = 8,
pages = 40,
url = {https://pagedout.institute/webview.php?issue=8&page=40}
} |
|---|
| ACM | Michał Nazarewicz. 2026. NTP-over-HTTP. In Paged Out!, 8 (February 2026), 40. https://mina86.com/2010/dni-wolnego-oprogramowania/ |
|---|
| APA | Nazarewicz, M. (2026). NTP-over-HTTP. Paged Out!, 8, 40. https://pagedout.institute/webview.php?issue=8&page=40 |
|---|
| IEEE | M. Nazarewicz, „NTP-over-HTTP,” Paged Out!, № 8, p. 40, Feb. 2026. [Online]. https://pagedout.institute/webview.php?issue=8&page=40 In case you’ve missed it, issue #8 of the Paged Out! magazine is out. Marking that occasion, I thought I’d share my ntp-over-http Rust implementation which was featured there. Did you ever need to synchronise a machine’s time without access to NTP (maybe because of a blocked port)? That’s exactly what the tool can help with. $ cargo install ntp-over-http
…
$ ntp-over-http
ntp-over-http: https://qwant.com/
2026-03-27 17:08:42 UTC For more details, caveats and other approaches, have a look at the NTP-over-HTTP article in the magazine. |
|---|
|
|---|